
专访原粒半导体:用「芯粒」方法重构AI芯片解决大模型推理算力需求
以下内容转载自问芯。
2022 年底 ChatGPT 的发布带来生成式 AI 的飞速发展,大模型应用领域已经从自然语言对话等文本生成拓展到综合了文本、语音、图像、视频等多种媒介的多模态生成式 AI 场景。
传统上,大模型的训练和推理都在云端数据中心完成,全球各个大模型巨头公司都投入了重金在数据中心建设上。今年 5 月下旬以来,国内的云端大模型推理服务价格跳水,大模型进入“白菜价”时代,降价之后各种领域的 AI 应用将“遍地开花”。
大模型应用普及的同时,也给 AI 大模型服务提供商带来了巨大的成本压力。推理价格的降低,必然要求服务提供商们能够同步降低他们的推理成本,服务商们不可避免地需要从早期不计成本地的客户争夺,向“降本增效”过渡,用更低成本的大模型推理硬件提供更多的大模型推理服务,是赢得“大模型大战”的重要支撑。
与此同时,大模型推理计算的场景正在从云端向边缘端延伸。借助云端数据中心进行大模型推理计算,存在数据传输延迟、服务端负载涨落等影响用户体验的因素,同时用户的数据隐私保护也是一个难以解决的问题。在一些对实时性以及隐私保护要求很高的场景,如智能座舱、自动驾驶、AI PC、具身智能等众多领域,通过将大模型部署在边缘端进行推理计算可以很好地弥补云端推理的不足,实现对用户数据更加安全和实时性更高的本地处理,大幅提升使用体验。
传统的单芯片 AI 加速器芯片以及 AI SoC 设计方法,目前已经遇到了包括晶圆制造工艺限制、研发制造成本高昂以及研发周期漫长等多方面的制约,难以跟上大模型的发展速度。作为半导体行业未来发展的新兴力量和热点,芯粒(Chiplet)技术在提高芯片算力、降低成本、提供灵活性和扩展性等方面具有天然优势,能够在云端和边缘端等各种应用场景下提供灵活的算力配置,为大模型的多场景部署提供广泛支持。
“大模型浪潮下,‘云、边、端’算力需求激增,大模型的爆发首先带动的是对云端训练算力的需求,随后,云端以及边缘端推理的算力需求也开始激增。芯粒技术为解决大模型爆发带来的算力需求瓶颈带来了更好的解决方案。”原粒(北京)半导体技术有限公司(简称原粒半导体)联合创始人原钢告诉「问芯」。
原粒半导体成立于 2023 年 4 月,是一家基于芯粒技术布局 AI 算力硬件的公司,专注于多模态 AI 处理器架构设计和芯粒算力融合技术,设计和生产低成本、高能效的通用 AI 芯粒产品,并配合来自合作伙伴的 CPU/SoC 芯粒等推出满足多模态大模型推理需求的 AI 芯片、AI 算力模组和加速卡等。

基于芯粒的方法重构 AI 芯片
谈及创立原粒半导体的初衷,原钢表示,主要是看到 AI 加速芯片领域出现了一些新的需求尚未得到满足,同时芯粒技术的发展会带来全新的市场机会。“此前,AI 推理芯片主要还是聚焦于满足卷积神经网络(CNN)的计算需求,而从 2022 年起 AI 芯片的研发热点逐渐开始转向以 Transformer 为核心的多模态模型,包括自然语言处理和图像生成模型等。然而,传统的 AI 芯片架构并不一定适用于高效的大模型推理计算,需要一些新的设计方法创新,例如研发专门针对大模型推理优化的 AI 计算架构以及使用芯粒技术实现灵活的算力扩展等。我们在去年创立了原粒半导体,希望基于芯粒技术,为市场提供性价比更高的多模态大模型推理解决方案。”他介绍说。
区别于传统的单硅片(monolithic)芯片的将所有核心组件放在同一个硅片(die)的设计范式,基于芯粒技术的计算芯片或 SoC 的设计理念是预先设计制造好具有特定功能、可组合集成的一系列硅片,并在封装制造过程中把它们集成起来。通过将原本集成在一整块芯片上部分核心处理器 IP 按功能拆分成一个个独立单元,可以按需求进行搭配组合,实现“即插即用”。
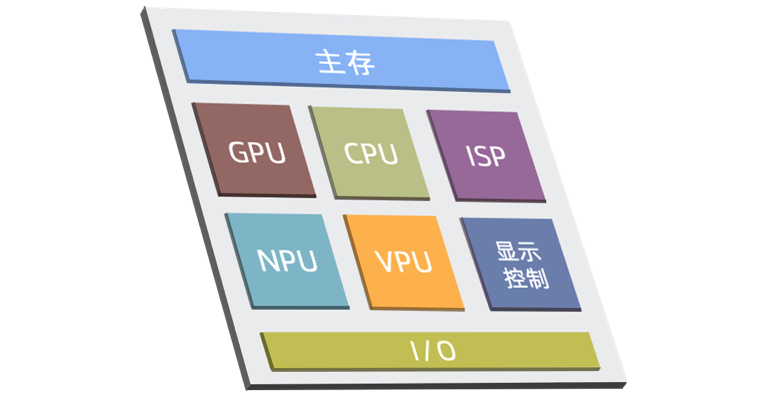
图|芯粒技术示意
“原粒半导体的核心产品是通用的多模态 AI 芯粒,然后根据目标场景不同的算力需求,通过组合不同规格和不同数目的芯粒,来为云边端提供最合适的算力解决方案。”原钢指出。
产品布局方面,原粒半导体根据不同行业客户的需求,以 AI 芯粒为核心推出不同形态的算力产品,包括 AI 芯粒(Known Good Die)、AI 芯片(比如和第三方 SoC 芯粒合封的芯片)、边缘端模组以及推理加速卡等。原钢表示:“未来,原粒会围绕大模型推理业务层面的需求,以及芯粒技术的发展趋势,包括互联接口标准,以及先进封装技术的演进等,不断为市场推出创新的 AI 大模型推理算力产品。”
事实上,Chiplet 也并非是一个全新的概念,其设计理念最早源于 1970 年代诞生的多芯片模组,而在这两年芯粒技术突然升温,在原钢看来,是由于随着摩尔定律因为物理极限而逐渐走向终结,伴随着顶尖先进工艺芯片的研发和制造成本高昂,传统的单硅片设计方法学提供的芯片演进速度已经难以跟上快速演进的大模型等新兴应用发展的脚步。而芯粒技术是解决芯片算力密度、研发制造成本以及算力灵活性等问题的最佳方案。
“以消费级 SoC 产品为例,过去 10 年来,市场上主流 SoC 产品的芯片制程工艺不断迭代演进,从 65nm、40nm 直到目前最先进的 3nm。然而制程工艺尺寸缩小终究会到达物理极限,并且随着制程工艺逐渐接近极限,制造成本呈指数级上升,流片成本从 65nm 的数十万美元增加到 3nm 的数千万美元。生产制造一颗采用顶级工艺的 SoC 的研发制造成本,大概只有苹果和高通这类有着庞大销售基数和毛利水平的公司能承受。”他说道。
“传统的单一硅片 SoC 会在一颗芯片上集成 CPU、GPU、NPU 等全部核心模块,每颗 SoC 芯片的研发都需要走一遍耗时且昂贵的流程,包括 IP 采购、前/后端设计、晶圆生产以及封测等等,开发一颗高性能 SoC 的成本是非常高的。而对于边缘端来说,AI 大模型的应用场景是十分多变的,不同垂直场景下往往需要不同的 SoC 功能和 AI 算力配置。如果用传统 SoC 的设计方法为每个应用场景提供最适合的算力,以及具备最佳性价比的 AI 芯片方案,很可能需要设计和生产很多规格的 AI SoC,导致研发成本很高。但是由于每个特定规格的 AI SoC 芯片销量又不一定能确保芯片厂商收回研发成本,这就给 AI SoC 产品的算力规划带来了一些困难。”原钢表示。
“用传统 SoC 的设计方法去满足大模型时代的 AI 算力需求有着诸多问题,而基于芯粒的方法可以把 AI 计算部分作为一个独立的可扩展选项,使用传统 SoC 和单独的 AI 芯粒在芯片封装设计层面进行集成。SoC 和 AI 芯粒可以分开设计和演进,通过搭配不同规格、数量的芯粒,满足不同场景不同算力需求。”他指出。
在数据中心领域,计算密度是一个很重要的指标,计算密度体现了在单位占地面积下数据中心的服务器能处理多少数据。对客户而言,在一个固定空间内能容纳的计算能力越高,其所需要承担的购买或租用物理空间的价格就越低。国际顶级数据中心芯片巨头如英伟达、英特尔以及 AMD 等都在想办法提高单颗 CPU 和 GPU 的计算性能,提高计算密度。提高单芯片计算密度的传统方法是把芯片尽量做大,比如英伟达的顶级 GPU,基本都把光罩(reticle)的有效面积用到了极致,所制造出的芯片 Die size 接近常规制造工艺物理极限。
“这种做法的缺点就是庞大的研发费用和比较低的生产良率,因此Xilinx在将近10年之前就用芯粒的方法来制造超大容量的 FPGA,而 AMD 也在很早之前就开始采用芯粒的方法来制造超多核数的服务器端 CPU,这些基于芯粒来提高计算密度的做法取得了巨大的商业成功,同时很好地控制了研发成本。”原钢说道,“我们看到,英伟达在它最新的 Blackwell 产品中终于也采用了芯粒技术来进一步提高 GPU 的计算密度。”

图|AMD MI300,采用 Chiplet 技术集成了 1460 亿个晶体管,AMD 史上最大芯片(来源:amd-cdna-3-white-paper)
“目前,国内的芯片制造工艺受到了一些限制,还处于努力追赶国际先进制程技术的过程中。就国内而言,现阶段想要提升算力密度,采用芯粒的方法是一条切实可行的技术路线。从封装级、板级和系统级提高算力密度,能够部分降低对于先进制程工艺的依赖,同时降低流片成本。”他指出。
“目前大模型的部分推理计算需求正在从云端向边缘端迁移,类似于 AMD、英特尔、高通等厂商目前正在力推的AI PC就是一个典型的例子,我们认为未来边缘端大模型推理计算的需求会非常旺盛。”原钢说道。
“然而,目前市面能够为多模态大模型推理提供足够算力的 SoC 还非常少。我们的策略是选择从芯粒切入,与研发 SoC 的合作伙伴开展合作。比如,将我们的 AI 芯粒与其他公司的 SoC 芯粒进行合封或是 PCB 级互联来推出完整的 AI 方案。整体而言,对比传统的 AI SoC 设计方法,基于芯粒方法的解决方案在研发成本、生产成本、算力灵活性、能效比、以及实现自主可控等方面都更具优势。”他总结道。

图|原粒半导体的 AI 芯粒配合 SoC 实现大模型端侧推理
为大模型推理专门优化实现更佳能效比和成本控制
原粒半导体自成立以来已经完成了多个方面的里程碑。据介绍,融资方面,公司已经完成种子轮、天使轮两轮融资,投资方包括英诺天使、中关村发展集团、中科创星、一维创投、清科创投、华峰集团、水木清华校友种子基金等。
“目前我们的核心 AI IP 研发进展顺利,设计基本完成,正处于全面验证阶段。AI 芯粒产品也会在明年和大家见面。”原钢介绍道,“目前大模型的应用场景正处于爆发前夜,我们希望在合适的时间准备好合适的大模型算力硬件,为智能座舱、具身智能机器人、AI PC 以及数据中心等众多领域提供完善的解决方案。中国人的想象力非常丰富,未来大模型的应用场景和落地产品也一定会十分丰富。”
技术层面,原粒半导体聚焦于研发两项关键技术,多模态AI计算核心(CalCore)和 AI 算力融合架构(CalFusion)。具体而言,CalCore 可适应当前多样性的 AI 算法发展趋势,除了针对多模态大模型等新兴算法进行深度优化,也保持了对传统 CNN 等算法的良好支持。CalFusion 能够支持多层次灵活的计算核心融合和扩展,可以利用多颗CalCore 芯粒或芯片在封装基板层面以及 PCB 层面进行堆叠和扩展,构建不同算力的 AI 解决方案,满足不同规格和成本需求的各种应用场景。

图|CalCore 和 CalFusion
围绕基于芯粒方法的 AI 算力芯片,原粒半导体提出了“积木式架构”。“所谓积木式架构,就是原粒的 AI 芯粒产品可以根据不同客户的不同功能、算力、功耗、成本等需求进行组合,实现一个较为灵活的配置。”原钢解释说,“大模型时代对于算力需求越来越多样化,从边缘端来讲,积木式架构能够很好的契合各种应用场景,推出多种灵活的算力配置方案,有效控制成本,实现一个最优的解决方案。”
在原钢看来,架构创新是原粒半导体的核心竞争优势之一,原粒专门为大模型的推理应用进行优化的 AI 计算核心和互联架构,能够实现更高的性能和更低的成本,这会是原粒半导体呈现给客户的核心价值。“同时,相比国外巨头,我们可能也更接地气。”原钢表示,“全球 AI 应用层面创新还得看中国,国内有非常庞大的消费市场,要服务好这个市场,AI 芯片公司需要满足国内市场的各种严苛要求,比如对于特异化功能、低成本、周边配套器件适配等的各种需求。在这些方面,国内芯片厂商往往更具优势,本地化的技术支持和快速的市场响应会给客户终端产品的开发带来不少便捷。”
访谈接近尾声,原钢总结说:“展望未来,大模型应用会持续演进,最终会无处不在。原粒半导体的 AI 芯粒产品也将顺应潮流不断迭代,基于技术趋势和市场反馈进行及时的调整优化,紧跟客户对于算法、算力、成本、功耗、以及应用领域的需求。我们希望未来在云边端等任何一个需要 AI 算力的场景,原粒都能做到用更低的成本提供更高的性能,给客户和 AI 产业带来价值。”
参考资料:
1.https://calculet.com.cn/
2.https://calculet.com.cn/hxjs